Understanding the Thundering Herd Problem
Why 10,000 users clicking "refresh" at the same time can bring down your entire system

Imagine you’re a backend engineer at a fintech app. The market is highly volatile, and your marketing team blasts a push notification to 10 million users: “Massive tech dip! Open the app to buy now!”
At exactly 9:30 AM, 3 million users tap it simultaneously.
They all instantly request the real-time pricing dashboard. Normally, Redis handles this smoothly. But there’s a fatal catch: the cache TTL for that pricing data expired exactly one millisecond ago.
Because the cache is momentarily empty, all 3 million synchronized requests bypass it and slam directly into your primary database. The connection pool exhausts instantly. CPU spikes to 100%. The database chokes, taking the entire app down right when users are desperate to trade.
This isn’t just a “traffic spike.” It’s an organized, synchronized assault on a limited resource. In system design, this is the Thundering Herd Problem. If you don’t design for it, it will take your entire backend down.
What Exactly Triggered the Herd?
Thundering Herd is a performance anti-pattern. It occurs when a large number of processes, threads, or clients are waiting for a specific event to happen. When that event finally occurs, all the waiting actors wake up simultaneously and aggressively compete for the same resource.
Because the resource (your database, your CPU, your connection pool) can only handle a few requests at a time, your system spends all its energy managing the contention—switching contexts, queueing, and failing rather than actually doing the work.
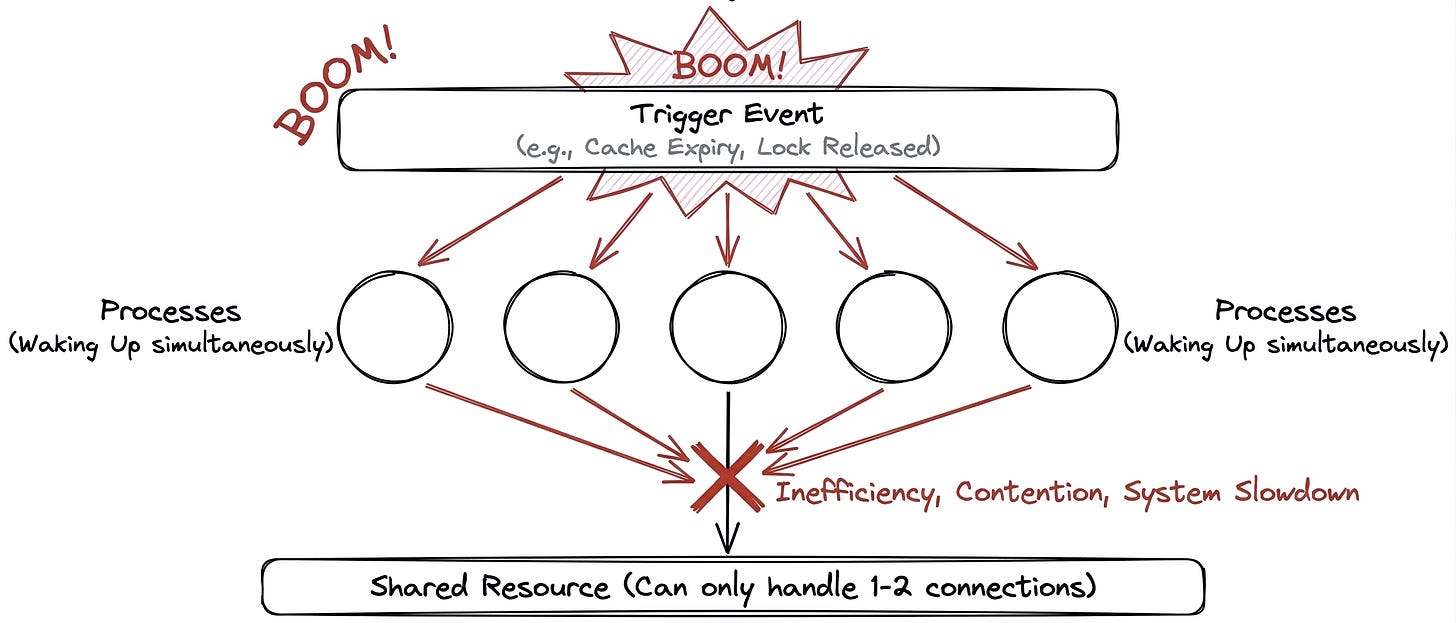
Where Does This Usually Happen?
Caching Systems: A popular cache key expires, and thousands of clients hit the database to re-fetch the data at the exact same time (The Cache Stampede).
Databases: Dozens of threads are waiting for a row-level lock. When released, they all wake up, but only one gets the next lock.
Load Balancers: A sudden influx of connections waking up all worker processes simultaneously (a wakeup storm).
Normal Traffic Spike vs The Thundering Herd
It’s easy to confuse a Thundering Herd with a normal traffic spike. Let’s break down the difference.
Normal Spike:
An increase in overall load driven by organic user growth.
While the volume of requests is high, they are distributed somewhat evenly over time. Your system might run hot, but it’s manageable. Standard auto-scaling has time to detect the load, spin up new servers, and handle the rush gracefully.
Example: Peak evening hours or a gradual increase in users.
Thundering Herd:
A synchronized, instant surge caused by a coordination or timing issue inside your architecture.
The defining characteristic is a massive burst of requests hitting at the exact same millisecond. Auto-scaling won’t save you here because the system doesn’t have time to react. It causes immediate resource contention, exhausted connection pools, and cascading failures.
Example: A cache TTL expiring, a database lock releasing, or a massive wave of simultaneous retries.
To put it simply: a normal spike is a busy highway during rush hour. A Thundering Herd is a hundred cars trying to merge into the exact same toll booth lane at the exact same time.
How Systems Collapse
When the herd hits, the damage is multi-layered:
Cache: If the herd is triggered by a cache miss, the cache becomes effectively useless for that specific key while everyone bypasses it to hit the source of truth.
Database: The DB gets hammered with hundreds of identical queries. Connection pools exhaust, and queries start timing out.
CPU: The application servers experience massive CPU spikes due to context switching—waking up thousands of threads just to put them back to sleep when they fail to acquire a lock.
Latency: End-users experience infinite loading spinners.
Why It’s a Nightmare in Distributed Systems
In a traditional monolithic app, a Thundering Herd might just crash your database and throw a 500 error to the user. It’s painful, but it’s contained. However, in a distributed microservice architecture, the herd acts like a virus, causing what we call a Cascading Failure.
Because microservices are heavily interconnected, a herd hitting Service C causes it to freeze. Service B, which is waiting on a response from C, starts stacking up pending requests until its own memory maxes out and it crashes. Service A sees that B is failing, panics, and violently starts retrying requests (Retry Storm) accidentally creating a second Thundering Herd.
One isolated cache miss doesn’t just take down a database; it knocks over your entire microservice ecosystem like a set of dominoes.
Real-World Case Study: Facebook’s Memcached Stampede
To understand how insidious this problem is, let’s look at one of the most famous engineering scaling challenges in internet history: Facebook in the early 2010s.
The Setup
Facebook’s architecture relied heavily on a massive caching layer called Memcached to protect its underlying MySQL databases. Whenever a user loaded a profile, the web servers (acting as clients) would check Memcached first. If the data was there, great. If not (a cache miss), the server would query MySQL, compute the result, and write it back to Memcached.
The Problem: The Cache Stampede
Some data on Facebook is absurdly popular. Imagine a massive celebrity updates their status. That data is cached, and millions of users are requesting it every second.
Eventually, that cache entry reaches its TTL (Time-To-Live) and expires.
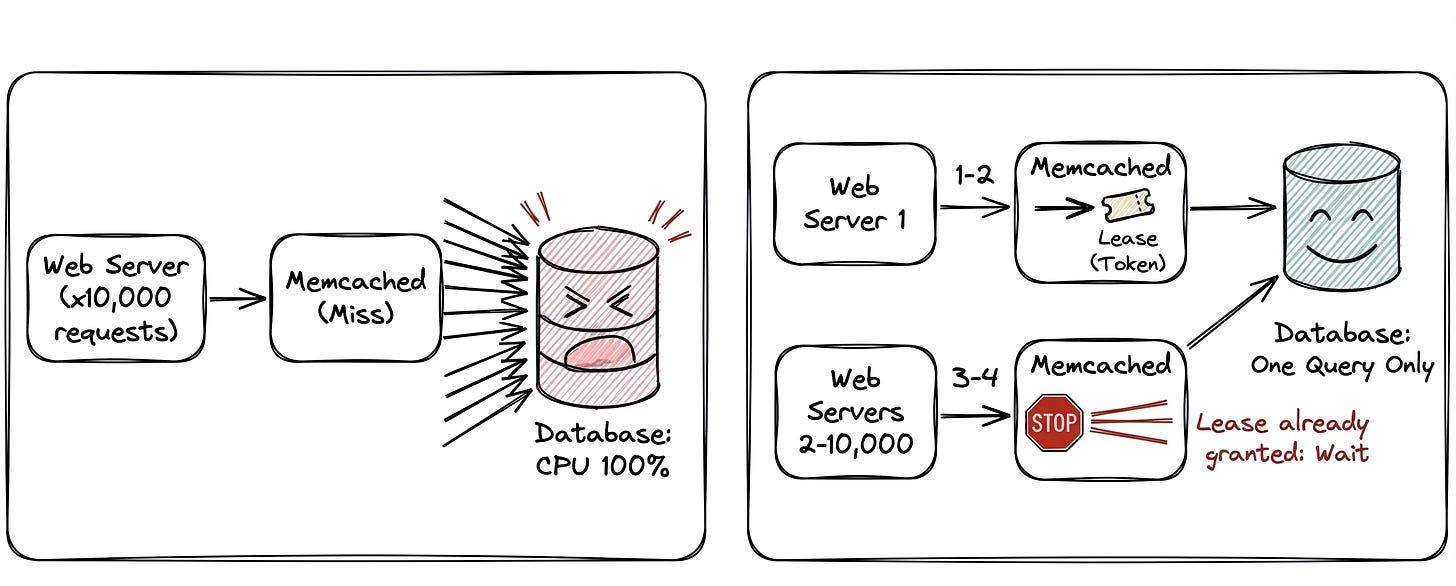
In a naive system, the next time those millions of users request the status, they all experience a cache miss at the exact same millisecond. Because the cache is empty, thousands of web servers simultaneously pivot and fire identical, heavy queries directly at the MySQL database.
MySQL wasn’t designed to handle 50,000 identical queries instantly. The database’s CPU spikes to 100%, connection pools exhaust, and the database grinds to a halt. Because the database is locked up, no one can write the fresh data back to the cache. The herd tramples the database, taking the whole site down with it.
The Solution: The Memcached “Lease”
Facebook engineers couldn’t just “scale the database” as that’s financially unsustainable. Instead, they had to act as traffic cops at the cache layer. They introduced a concept called Leases (a form of Mutex/Cache Locking).
Terminology Breakdown: A Mutex (Mutual Exclusion) is a lock that guarantees only one thread or process can access a shared resource at a time.
Here is how Facebook changed the game:
When the cache expires, thousands of requests hit Memcached.
Instead of returning a simple “Cache Miss” to everyone, Memcached generates a Lease (a special 64-bit token) and gives it to the very first request.
The first request takes the Lease, goes to the MySQL database, and starts doing the heavy lifting to fetch the new data.
When the other 9,999 requests hit Memcached, they don’t get a Lease. Memcached tells them: “Hold on, someone else is already fetching this. Wait a few milliseconds.”
By simply handing out a single token, Facebook forced the Thundering Herd to wait in line. The database only received one query instead of 10,000. Once the first server updated the cache, the other 9,999 servers woke up, read the fresh data directly from the cache, and happily moved on.
Other Preventive Techniques:
Facebook’s Lease mechanism is brilliant for protecting databases, but there are other ways to handle the herd depending on your architecture.
1. TTL Jitter (Staggered Expiry)
If you set 10,000 cache keys to expire at exactly 12:00:00, you have a herd. If you add Jitter (TTL = 60mins + random(0, 5mins)), they expire gradually, smoothing out the database load.
2. Request Coalescing (Deduplication)
Similar to Leases, but handled at the application tier. If 500 requests hit your backend for the same missing data, you merge them into one “in-flight” promise. Only one DB call is made, and all 500 clients resolve from that same promise.
3. Stale-While-Revalidate (SWR)
Never block the user. If the cache is expired, serve them the stale (old) data immediately, but trigger a background process to fetch the fresh data. Perfect for high-availability systems where a few seconds of outdated data is acceptable.
The End
The Thundering Herd problem isn’t a symptom of having too many users; it’s a symptom of having too much synchronization. In system design, slight unpredictability (like jitter) and controlled bottlenecks (like locks) are often what keep the lights on.

